
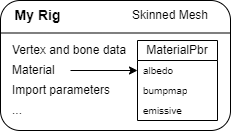
The idea of meshes with separately applied materials is intuitive, and mimics our real life understanding of form vs texture. And while this is a useful (if not mandatory) abstraction for game artists to author their creations, it simply isn’t how the GPU reasons about things – it’s our job to help it understand.
The GPU doesn’t care about “meshes” or “materials” per-say – what it cares about are data and very specific data transformations. And while this model can be applied to software more generally (thank you Mike Acton), it’s the “very specific” part and constraints of the graphics API that make this hard.

In my system, I currently use YAML files with “file watchers” for instantaneous in-engine updates. The following material definitions were used to generate the GIF above:
material: !mat_pbr
cell_shaded: true
roughness: 0.85
texture_scale: 1024
albedo_path: "Naomi/Body_Albedo.png"material: !mat_pbr
texture_scale: 2048
albedo_path: "StoneWall_2K/albedo.jpg"
normals_path: "StoneWall_2K/normal.jpg"
roughness_path: "StoneWall_2K/roughness.jpg"
roughness: 0.9material: !mat_effect
blend_mode: vivid_light
texture_scale: 1024
exposure_amount: 0.01
color_mul: [1.5]
channels:
- texture_path: "effect/SFX_Voronoi_1.png"
uv_transform: !aff_scale [2.0, 0.25, 1.0]
uv_translation_per_sec: [0.07, -0.05, 0.0]
- texture_path: "effect/SFX_Voronoi_1.png"
uv_transform: !aff_scale [2.0, 0.25, 1.0]
uv_translation_per_sec: [0.04, 0.05, 0.0](You could just as easily derive an in-game GUI for instance, but this was more expedient at the time I wrote it.) In any case, to decouple meshes from materials, I set the following goals:
- For artists, materials should consist of only a material type and instance. Types define parameters and their interpretation, whereas instances are just sets of arguments to these parameters. How all this get mapped to shaders under the hood is none of their concern.
- Each conceptual material type should map to precisely one definition. I.e. we shouldn’t have to redefine material types for purely technical reasons. However, if we want to eliminate texture samples for “pure white” instances, or expose “emissive light color” as a parameter and switch shaders when it’s zero, the solution gets rather complicated.
- A material instance should be able to draw anywhere in the pipeline, or in multiple places in the same frame. This is to facilitate multi-pass algorithms or materials drawn in multiple culling passes, e.g. a specialized shadow implementation.
- Building and issuing draws should be as fast as possible. This means optimizing for cache coherency, doing as much work as we can in advance, and utilizing the latest graphics API features to batch our data and reduce driver overhead. (E.g.
ARB_multi_draw_indirectorNV_command_list.)
To solve the above concerns, we’ll use the following definitions:
- mesh: formatted data specified by an artist, fed to a selected mesh transform.
- mesh transform: an object that transforms a mesh into a list of vertices to be interpolated for use by the fragment shader.
- culling pass: a traversal of the game scene with a given view and frustum, used to accumulate “draws” of visible objects.
- batch: a group of draws stored together in memory and drawn all at once, potentially more than once per frame.
- batch key: a unique tuple
<mesh transform ID, material type ID, material case bits>associated with one batch per relevant culling pass and a single shared material list. All draws share the elements of the tuple in common, and can therefore be drawn together by one call to the graphics API. - technique: an object representing the enclosing state of any given draw or batch, (i.e. rasterizer state, shader bindings, texture bindings, etc.) and a fixed location within the graphics pipeline. Generally maps to a graphics API “state object.”
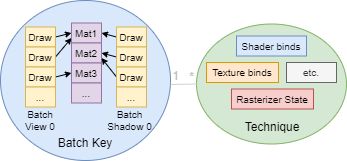
We want to allocate as few techniques and batches as possible given the entire set of draws – by using batch keys, we can solve this optimally, ensuring that draws are stored in at most one batch, which in turn simplifies the client’s work during culling.
Building batches
Everything is stored in arrays-of-structs. Batch keys are registered to the API during asset load and are represented by a simple batch index. (We prefer this to the key to avoid overhead from hashtable lookups.) Upon a batch key’s first registration, all necessary techniques are generated on the back-end.
private val batchIndex = batches.acquireBatchesFor(meshTransform.index, matType.index, matCaseBits)
override fun destroy() {
batches.releaseBatches(batchIndex)
}At cull time, we pass the batch index along with the current culling pass’s information to our API to retrieve the batch, then enqueue whatever draws are necessary.
private val cullPassMask = matType.getCullPassMask(matCaseBits)
override fun doCullingPass(context: CullContext, passId: Int, passIndex: Int) {
if (cullPassMask.isBitClear(passId)) return
if (!context.frustum.intersects(/*...*/)) return
val batch = batches.getBatch(passId, passIndex, batchIndex) as? MyBatch? ?: return
batch.append(/* draw data */)
}Then just before draw commands are submitted, the system traverses the entire array of batches and “scatters” non-empty ones to the techniques that will draw them. This is the complete process as far as acquiring a batch and submitting draws is concerned – but clients still have some work to do to make their materials visible to the API.
Building material instances
Recall that a batch key is a unique combination <mesh transform ID, material type ID, material case bits> – in particular, this does not include any material instance data for use in-shader. To provide this data to our API, we define a material list for each batch key, retrievable by index. Clients may ask the list to allocate blocks of memory for material instances they’d like to define, each accessible via a material index.
Then depending on the mesh transform, the list and indices are used to either:
- Bind a single uniform block before each draw via
glBufferBindRange(or equivalent, e.g. usingNV_command_listto combine into one operation.) - Bind a uniform-buffer-object (UBO) just before the batch is drawn, allowing array access in-shader (e.g. to support instancing with per-instance material indices.)
But how do we convert artist-defined data into GPU data in the first place? One possibility is to define a class like this:
abstract class MaterialObject {
val changeListeners = LinkedHashSet<() -> Unit>()
fun generateGui(): Gui { /* scan members reflectively*/ }
protected fun onChanged() { changeListeners.forEach { it() } }
abstract fun updateGpuData(struct: Long)
}
class MaterialPbr : MaterialObject() {
var albedoPath: String? = null ; set(v) { field = v; onChanged() }
var albedoRgba = 0xffffffff ; set(v) { field = v; onChanged() }
// ...
override fun updateGpuData(struct: Long) { /* Write to pointer. */ }
}Where MaterialObject uses reflection to generate a GUI for our artist-facing properties, then populates GPU data upon request. But in our setup, clients also have the option of generating GPU data themselves.
When we have many instances of a mesh that use roughly the same material, but with slight variations depending on specifics of the instance, being able to avoid MaterialObjects is really handy – this allows us to eliminate memory for mostly-redundant material information, and particularly in a language like Kotlin or Java, avoid allocating and dereferencing a number of heap objects. (Recall the goal of cache coherency!) However, actually allowing this by making our API agnostic toward MaterialObject will prove to be complex, as we’ll see later on.
Building shaders
Going back to our analogy, if we think about materials as texture and meshes as form, it becomes apparent that different stages of the OpenGL rendering pipeline map naturally to either material or mesh. In particular, stages operating on conceptual vertices map to a mesh transform, i.e. vertex, tessellation, and geometry shaders (or mesh and task shaders via NV_mesh_shader), meanwhile the fragment shader maps cleanly onto a material.
In our system, we keep the mesh transform simple, containing only shaders, some flags, and the ability to prepend UBOs to associated batches. But the material type takes responsibility for interpreting the output attributes of the mesh transform correctly, and it’s this generalized support for attributes that adhere to an “interface” that makes our fragment shaders complicated.
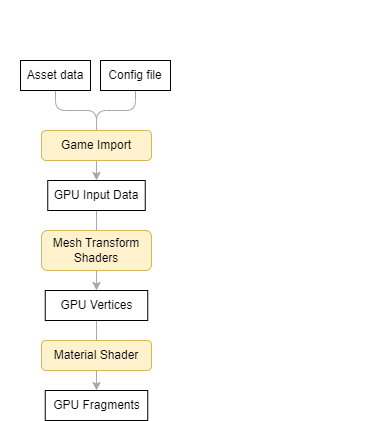
When the mesh transform and material type are first combined, the type scans all output attributes of the transform’s last shader, checking their names and types against the ones it knows how to handle (e.g. vec4 pass_Color, vec3 pass_Normal, etc.) It then injects #defines into an extremely macro-heavy fragment shader to select corresponding input attributes and handling code. (Here we’re heavily leveraging the fact that OpenGL eliminates unbound output attributes.)
What this means is that every material type must define at least one heavily boilerplate fragment shader – but the payoff of decoupling materials from meshes is a net code decrease! Even then, the boilerplate can be reduced in a number of ways depending on the investment we’re willing to make (e.g. writing a script or node-based material authoring system) – but that’s a topic for another time!
Building techniques
Thus far, we’ve defined material types as a set of artist-facing parameters and as a generator of fragment shaders. Intuitively, to interpret these parameters it must define the technique (which the fragment shader belongs to).
Simply defining one technique would be a fine start, but we’d like material types to generalize across multiple techniques, encapsulating differences such as shader #defines, OpenGL draw state, etc. We need this in order to:
- Avoid significant code and data duplication every time we want a minor tweak.
- Support complex materials or multi-pass algorithms that need the ability to draw at multiple locations within the pipeline.
For any one material type, the back-end can create as many techniques as necessary to achieve this – but coders should never have to manually specify a second material type that’s “exactly the same but without a roughness map” or “with 2x texture scale,” or “the auxiliary shadow material,” etc. (And artists shouldn’t even have to think about this!) These variations are conceptually the same type, and the highest level of the API should reflect this.
To support all the above, we define per-material instance caseBits, which are passed in as part of the batch key (i.e. as material case bits). These caseBits generally represent swappable features of the material instance (e.g. hasEmissiveLight or effectCombineMode) that the type can use to infer which techniques are applicable. The client declaring the key can derive these bits from either a MaterialObject that knows how to populate them, or a simple bitmask composed of the features the client knows they need. With this we have the final element of our batch key!
To handle the two cases of technique multiplicity that we described earlier, we establish a general mechanism of interpreting caseBits that will map material instances to their appropriate techniques: a per-material-type list of technique slots, each of which has a tuple <cullPass, matchMask, matchBits, splitBits>.
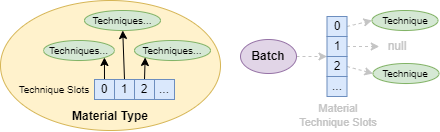
If a batch key’s caseBits match a technique slot of its material type ID (i.e. ((caseBits ^ matchBits) & matchMask) == 0), a batch will be culled during cullPass and drawn with a technique identified by the slot – this accomplishes the goal of drawing the same batch across multiple locations within the pipeline. Furthermore, within a slot, one technique shall be generated for each set of batches with equivalent caseBits & splitBits –splitBits can therefore be used to specify which caseBits encode same-pass variants of the technique.
Implementing the generation and lifecycle of these techniques is non-trivial, but performance isn’t as critical since this process only occurs upon a batch’s first acquire, typically during a load screen, and will be dwarfed by the driver expense of allocating the batch anyway. What is critical however is resolving techniques and batches quickly within the render frame, which is why we simply store everything in large arrays and use indices to identify our batches.
What it all looks like
Now that we’ve elaborated this system, let’s take a look at the code.
Be forewarned that this is heavily simplified, so if you’re saying to yourself, “Hmm, that results in an unnecessary allocation…” you’re absolutely right and it’s probably not happening in the real version!
We’ll start with acquiring and using a batch, then work our way towards defining a mesh transform and material type. We omit the implementation of batch and technique lifecycle, as it is probably best understood from API usage and reading the above.
Using the API
The first example is without any explicit MaterialObject, i.e. we handle the setup of GPU material instances ourselves. We have a SimpleLightBehavior that not only renders lights on the screen, but draws per-light spheres that need a special material:
class SimpleLightBehavior(
private val batches: RenderBatches, // our API
// other properties...
) : GameBehavior() { // Kotlin inheritance
class SimpleLight { // Kotlin nested class, no reference to outer class
// various properties...
internal var matIndex = -1
internal var isMatDirty = true
internal fun initialize(/* ... */, matList: SmartGpuBuffer?): SimpleLight {
// setup our properties...
matIndex = matList?.alloc() ?: -1 // Kotlin null-safety
return this
}
internal fun destroy(matList: SmartGpuBuffer?) {
if (matIndex != -1) {
matList!!.free(matIndex) // !! throws if null
matIndex = -1
}
// cleanup our properties...
}
internal fun writeMat(mat: MaterialPbrStruct) {
// write out properties to mat, which is a "pointer class"
}
}
// List of lights we maintain:
private val lightsList = RawArrayList<SimpleLight>()
private val lightPool = ObjectPool { SimpleLight() }
// Batch information:
private val matType = batches.getMaterialType(MaterialPbr.TYPE_ID)!!
private val matCaseBits = MaterialPbr.BIT_DRAW_MAIN or MaterialPbr.BIT_WRITE_EMISSIVE
private var batchCullPassMask = 0x0
private var transformIndex = -1 // mesh transform
private var batchIndex = -1
// Called once at top level.
// We expect to receive a "Sphere Instances" mesh transform index:
fun setupBatch(transformIndex : Int) {
check(transformIndex >= 0)
this.transformIndex = transformIndex
batchIndex = batches.acquireBatchesFor(transformIndex, matType.index, matCaseBits)
batchCullPassMask = matType.getCullPassMask(matCaseBits)
val matList = batches.getMaterialList(batchIndex)
if (matList != null) lightsList.forEach { it.matIndex = matList.alloc() }
}
// Called once at top level:
fun tearDownBatch() {
if (batchIndex == -1) return
val matList = batches.getMaterialList(batchIndex)
if (matList != null) {
lightsList.forEach {
if (it.matIndex != -1) {
matList.free(it.matIndex)
it.matIndex = -1
}
}
}
batches.releaseBatchesFor(batchIndex)
batchIndex = -1
batchCullPassMask = 0x0
}
// Creating a light upon request:
fun createFor(/* ... */): SimpleLight {
val matList = if (batchIndex < 0) null else batches.getMaterialList(batchIndex)
val newLight = lightPool.get().initialize(..., matList)
lightsList += newLight
return newLight
}
// Removing a light upon request:
fun remove(light: SimpleLight) {
lightsList.remove(light)
val matList = if (batchIndex < 0) null else batches.getMaterialList(batchIndex)
light.destroy(matList)
lightPool.takeBack(light)
}
// GameBehavior API, giving us access to the game loop.
// We want to update any dirty materials before drawing.
override fun onCullingBegin(context: CullingContext) {
val matList = batches.getMaterialList(batchIndex) ?: return
for (light in lightsList) {
if (light.matIndex == -1 || !light.isMatDirty) continue
light.isMatDirty = false
val tempMat = ... // temporary memory
light.writeMat(tempMat)
matList.write(light.matIndex, tempMat.ptr, MaterialPbrStruct.STRIDE)
}
}
// GameBehavior API, giving us access to the game loop.
// Here we do the actual work of culling the light's shape.
override fun doCullingPass(passId: Int, passIndex: Int, context: CullingPassContext) {
if (batchCullPassMask.isBitClear(passId)) return
val temps = Temp.MAIN
val viewFrustum = ...
// Get the batch, which we expect to be of a specific type based on the mesh transform
val batch = batches.getBatch(passId, passIndex, batchIndex) as? LoddedInstanceBatch?
for (light in lightsList) {
if (!light.isEnabled) continue
if (!light.doesIntersectFrustum(viewFrustum)) continue
if (passId == CullPass.VIEW) {
// Draw the light itself here (i.e. not the mesh)...
}
if (batch != null && light.matIndex != -1 && light.lightSphereRadius != 0f) {
// We draw the mesh here.
// Here, a batch is composed of multiple LODs,
// and each LOD has an instance list.
val lodDistanceSq = light.pos.distanceSqTo(context.lodCenter)
val sphereScale = 2f * light.sphereRadius
val buffer = batch.getAccumForLodSq(lodDistanceSq, sphereScale).buffer
// Function that knows how to append to 'buffer':
SimpleSphereInstances.pushInstance(
light.pos,
0f, 0f, 0f, 1f, // orientation quat
sphereScale,
light.colorRgba,
light.matIndex
buffer)
}
}
}
}That’s it! Assuming the MeshTransform and MaterialType have been set up correctly, batches will take care of the rest, ensuring our spheres are drawn.
In this case, we have only one constant batch for the entire class, which makes it easy to understand – but in a component-based architecture, a single class may represent a mesh and parameterize its material as a MaterialObject. This is the example we’ll examine next, which supports loading in a “worker thread” context:
abstract class SingleBatchComponent(
name: String,
protected val batches: RenderBatches, // our API
val material: MaterialObject, // extension to our API
) : PRigComponent(name) {
init { material.acquire() }
protected var reachedMainThread = false ; private set
protected var batchIndex = -1 ; private set
protected var batchMatIndex = -1 ; private set
/** -1 is a legal "no transform" value, which results in no batch being acquired. */
protected var transformIndex = -1
set(v) {
if (field == v) return
if (!reachedMainThread) {
field = v
} else {
tearDownBatch()
field = v
setupBatch()
}
}
override fun destroy() {
if (reachedMainThread) onLeftMainThread()
material.release()
}
override fun onReachedMainThread(device: GLDevice) {
reachedMainThread = true
setupBatch()
material.addBatchChangeLister(onMatBatchCaseChanged).assertTrue()
}
protected open fun onLeftMainThread() {
check(reachedMainThread)
material.removeBatchChangeLister(onMatBatchCaseChanged).assertTrue()
tearDownBatch()
reachedMainThread = false
}
private fun setupBatch() {
check(reachedMainThread)
if (transformIndex == -1) return
batchIndex = batches.acquireBatchesFor(transformIndex, material.typeIndex, material.caseBits)
batchMatIndex = material.registerToBatch(batchIndex) // maintains GPU memory for us
}
private fun tearDownBatch() {
check(reachedMainThread)
if (transformIndex == -1) return
material.unregisterToBatch(batchIndex)
batchMatIndex = -1
batches.releaseBatchesFor(batchIndex)
batchIndex = -1
}
// Responds to changes of 'material' properties, which may entail
// a change of batch due to a change in caseBits.
private val onMatBatchCaseChanged = { mat: Material, oldBits: Int, newBits: Int ->
check(reachedMainThread)
if (transformIndex != -1) {
mat.unregisterToBatch(batchIndex)
batches.releaseBatchesFor(batchIndex)
batchIndex = batches.acquireBatchesFor(transformIndex, mat.typeIndex, newBits)
batchMatIndex = mat.registerToBatch(batchIndex)
}
}
}
// Subclass that performs actual cull:
class SimpleSphereComponent(
name: String,
material: Material,
batches: RenderBatches,
transformIndex : Int, // computed by declaring module (we'll show this later)
) : SingleBatchComponent(name, material, batches) {
init { this.transformIndex = transformIndex }
// various properties...
override fun doCullingPass(context: RigCompDrawContext, passId: Int, passIndex: Int) {
// 'batchIndex' here is a property of our superclass:
val batch = batches.getBatch(passId, passIndex, batchIndex) as? LoddedInstanceBatch? ?: return
val pos = // compute position...
val quat = // compute orientation...
val scale = // compute scale...
// Again, we have a LOD-ed instancing scheme:
val distanceSq = context.lodCenter.distanceSqTo(pos)
val buffer = batch.getAccumForLodSq(distanceSq, instanceScale).buffer
// Function that knows how to append to 'buffer':
SimpleSphereStrategy.pushInstance(
pos, quat, scale,
ColorUtils.multiply(albedoRgba, context.colorRgba),
batchMatIndex,
buffer)
}
}You’ll notice some similarities with the previous case: we’re again assuming a MeshTransform of “instanced sphere” (this time inherent to the class SimpleSphereComponent). The superclass SingleBatchComponent does some bookkeeping to maintain a current batch and allows changing its transform at run-time, which results in releasing the old batch and acquiring a new one.
Of course, MaterialObject representing artist-facing data also has run-time changeable properties, which may or may not entail a change of batch. But because it is decoupled from batches generally, it’s the client’s responsibility to listen for changes and swap out any batches it has acquired using the material. SingleBatchComponent‘s purpose is basically to encapsulate this process.
So what about defining mesh transforms for use? Let’s take a look:
class SimpleSphereModule(
private val rigs: RigModule, // base module for all rig components
private val render: GameRender, // top-level class with render-related objects
private val batchPreamblerView: BatchPreambler, // injects external UBOs
lodCount: Int,
) : IDestroyable {
// We expose a "YAML bean" that knows how to instantiate our component:
private val yamlTypeDescs = YamlTypeDescriptionSet(
YamlComponentSimpleSphere::class to "!sphere",
)
init {
rigs.yamlNamespace += yamlTypeDescs
rigs.yamlContextMap.addSingleton(this) // so YAML bean can pass our
} // transformIndex to the component
// Here we build the mesh transform using a very basic Kotlin DSL.
// We configure a bunch of parameters, and setup the list of LOD-ed meshes.
var transformIndex: Int ; private set
init {
render.meshTransforms.build { // DSL scope
transformIndex = add(LoddedInstancedMeshTransform(
name="Simple Spheres",
drawMode=DrawMode.TRIANGLE_LIST,
useMaterialIndex=true, // we're instanced, so output material index attribute
batchPreambler=batchPreamblerView,
vaoLayout=SimpleSphereInstances.makeLayout(device), // OpenGL vertex array layout
shaders=arrayOf(shader("instanced_simple_mesh.glvs")), // DSL acquires shader
meshType=LoddedInstancedMeshTransform.MeshType(
name="Sphere",
instanceCapacity=0x800,
baseVertexScale=1f / (2 shl lodCount).toFloat(),
meshesByLod=Array(lodCount) { lod ->
MeshGeneration.createSphereMesh(DrawMode.TRIANGLE_LIST, /*...*/)
},
),
))
}
}
override fun destroy() {
rigs.yamlNamespace -= yamlTypeDescs
rigs.yamlContextMap.removeSingleton(this)
render.meshTransforms.removeFormat(transformIndex)
transformIndex = -1
}
}It might seem tedious, but the beauty is we only have to define it once! Now the mesh transform is compatible with any material defined using our API.
Speaking of which, let’s see how a material type is written:
object MaterialTypePbr : MaterialType("PBR", techniqueSlotData=intArrayOf(
// cullPassId, matchMask matchBits splitBits
NebRaxCullingPasses.VIEW, BIT_DRAW_MAIN, BIT_DRAW_MAIN, getCaseMask((BIT_SHADOW_CASTER or BIT_DEBUG_NORMALS).inv(), withTex=true),
NebRaxCullingPasses.SHADOW, BIT_SHADOW_CASTER, BIT_SHADOW_CASTER, getCaseMask(0, withTex=false), // helper method to inject texture bits
NebRaxCullingPasses.VIEW, BIT_DEBUG_NORMALS, BIT_DEBUG_NORMALS, getCaseMask(0, withTex=false),
)) {
override fun getStride(matCaseBits: Int): Int = MaterialPbrStruct.STRIDE
override fun appendBatchPreamble(matCaseBits: Int, matList: SmartGpuBuffer?, passId: Int, passIndex: Int, batch: PFormattedDrawBatch) {
matList?.appendBatchPreamble(CommonUboBindings.MATERIAL, batch)
}
context(TechniqueGenContext)
override fun generateTechnique(slot: Int, meshTransform: MeshTransform, matCaseMask: Int, matCaseBits: Int, matList: SmartGpuBuffer?): Boolean {
with(MyGameTechniqueGenContext()) {
when (slot) {
0 -> { // Deferred, with or without emissive
// Our game sets some bits aside to specify the texture size:
val shaderCaseBits = getCaseBitsShaderCaseBits(matCaseBits)
val textureScaleLog2 = getCaseBitsTexScaleLog2(matCaseBits)
val writeEmissive = shaderCaseBits and BIT_WRITE_EMISSIVE != 0
val stage = if (writeEmissive) PipelineStage.DEFERRED_EMISSIVE else PipelineStage.DEFERRED
configure(stage.ordinal) // helper method set appropriate technique defaults based on pipeline stage
val texIdGeneralColor = "scene.general_color_s$textureScaleLog2"
val texIdGeneralCh1 = "scene.general_ch1_s$textureScaleLog2"
val texIdGeneralNormals = "scene.general_normals_s$textureScaleLog2"
// "technique" here is a field of the passed in context:
if (shaderCaseBits and BIT_TEX_ALBEDO != 0) technique.bindSampler("albedo", texIdGeneralColor)
if (shaderCaseBits and BIT_TEX_NORMALS != 0) technique.bindSampler("normal", texIdGeneralNormals)
if (shaderCaseBits and BIT_TEX_ROUGHNESS != 0) technique.bindSampler("roughness", texIdGeneralCh1)
if (shaderCaseBits and BIT_TEX_PARAM != 0) technique.bindSampler("param", texIdGeneralCh1)
if (shaderCaseBits and BIT_TEX_EXTRA_COLOR != 0) technique.bindSampler("extraColor", texIdGeneralColor)
if (shaderCaseBits and BIT_TEX_EMISSIVE != 0) technique.bindSampler("emissive", texIdGeneralColor)
// Our method to do non-MaterialType related legwork for external reuse (not shown):
completeTechnique(stage, meshTransform.shaders, meshTransform.lastShaderType, matList)
}
1 -> { // Shadows
val stage = PipelineStage.SHADOW
configure(stage.ordinal)
completeTechnique(stage, meshTransform.shaders, meshTransform.lastShaderType, matList)
}
2 -> { // Debug normals
if (meshTransform.shaderTypeBits.isBitSet(ShaderType.GEOMETRY.order)) return false // Can only inject if geometry shader not already present!
val stage = PipelineStage.DEBUG_NORMAL
configure(stage.ordinal)
completeTechnique(stage, meshTransform.shaders, meshTransform.lastShaderType, matList)
}
else -> error("Unrecognized technique slot $slot!") // should never happen, assuming technique slot data well defined.
}
return true
}
}
context(TechniqueGenContext, MyGameTechniqueGenContext)
private fun completeTechnique(stage: PipelineStage, meshShaders: Array<out Shader>, lastMeshShaderType: ShaderType, matList: SmartGpuBuffer?) {
// We try to be attribute prefix agnostic, but still require one to exist.
// This allows shader stages to play nice, and the fragment shader
// to be agnostic towards the preceding shader stage.
val attrPrefix = determineAttributePrefix(meshShaders, lastMeshShaderType, "out")
when (stage) {
PipelineStage.DEFERRED,
PipelineStage.DEFERRED_EMISSIVE -> {
techniqueRequire(attrPrefix != null) { "Expected to find attributes with a prefix followed by an underscore, e.g. \"pass_Color\". Shaders: $meshShadersStr" }
val writeEmissive = stage == PipelineStage.DEFERRED_EMISSIVE
// Which samplers we're using:
val hasAlbedoSampler = technique.isSamplerBound("albedo")
val hasNormalSampler = technique.isSamplerBound("normal")
val hasRoughnessSampler = technique.isSamplerBound("roughness")
val hasParamSampler = technique.isSamplerBound("param")
val hasExtraColorSampler = technique.isSamplerBound("extraColor")
val hasEmissiveSampler = technique.isSamplerBound("emissive")
val needsUvs = hasAlbedoSampler || hasNormalSampler || hasRoughnessSampler || hasParamSampler || hasExtraColorSampler || hasEmissiveSampler
if (writeEmissive && !technique.isSamplerBound("preExposure")) technique.bindSampler("preExposure", "pre_exposure") // Necessary since emissive is applied post-lighting
// Object indicating presence of all "standard" attributes in our game:
val attr = findStandardAttributes(meshShaders, lastMeshShaderType, attrPrefix)
// Declare our shader and pass in defines:
shader("gbuffer/write_pbr.glfs") { defines ->
defines["ATTR_PFX"] = attrPrefix
// Material list injects shader code so it can be read, regardless of its implementation:
matList?.putShaderDefines("MAT_BLOCK", defines)
// Helper methods that inject standard defines for attributes:
val texDimsOut = attr.texDims + (if (matList == null) 0 else 1)
setupTexCoords(needsUvs, attr.texDims, texDimsOut, defines)
setupColorAlpha(attr.color, attr.alpha, attr.colorAlpha, defines)
setupNormals(attr.normal, attr.tangent, hasNormalSampler, defines)
if (hasAlbedoSampler) defines["ALBEDO_SAMPLER"] = "albedo"
techniqueRequire(!attr.roughness || !attr.roughnessFlagsParam) {
"Expected at most one of the following out attributes: 'float pass_Roughness', 'vec3 pass_RoughnessFlagsParam'! Shaders: $meshShadersStr"
}
if (attr.roughness) defines["ROUGHNESS_ATTR"] = "true"
if (attr.roughnessFlagsParam) defines["RFP_ATTR"] = "true"
if (hasRoughnessSampler) defines["ROUGHNESS_SAMPLER"] = "roughness"
if (hasParamSampler) defines["PARAM_SAMPLER"] = "param"
if (attr.extraColor) defines["EXTRA_COLOR_ATTR"] = "true"
if (hasExtraColorSampler) defines["EXTRA_COLOR_SAMPLER"] = "extraColor"
if (writeEmissive) {
defines["WRITE_EMISSIVE"] = "true"
if (attr.emissive) defines["EMISSIVE_ATTR"] = "true"
if (hasEmissiveSampler) defines["EMISSIVE_SAMPLER"] = "emissive"
}
}
}
PipelineStage.SHADOW -> {
// if no alpha is given, then "no fragment shader" is the best option,
// since we're just writing depth. Make it easy for the driver...
if (attrPrefix != null) {
val attr = findStandardAttributes(meshShaders, lastMeshShaderType, attrPrefix)
if (attr.alpha || attr.colorAlpha) {
shader("gbuffer/write_pbr_depth.glfs") { defines ->
setupAlpha(attrPrefix, attr.alpha, attr.colorAlpha, defines)
}
}
}
}
PipelineStage.DEBUG_NORMAL -> {
techniqueRequire(attrPrefix != null) { "Expected to find attributes with a prefix followed by an underscore, e.g. \"pass_Color\". Shaders: $meshShadersStr" }
val attr = findStandardAttributes(meshShaders, lastMeshShaderType, attrPrefix)
techniqueRequire(attr.posVS != 0) { "Expected output attribute 'vec3 pass_PositionVS'! Shaders: $meshShadersStr" }
techniqueRequire(attr.normal) { "Expected output attribute 'vec3 pass_Normal'! Shaders: $meshShadersStr" }
// This time we pass in defines as a map:
shader("nr_gen_normals.glgs", mapOf(
"IN_POSITION" to "pass_PositionVS",
"IN_NORMAL" to "pass_Normal",
"OUT_COLOR" to "pass_Color",
))
shader("simple/color.glfs")
}
else -> throw IllegalArgumentException("Unrecognized technique stage $stage!")
}
}
}Whew! That was a lot, but what’s most significant here is the ease of syntax – there are a lot of features to toggle via #defines, and we try to keep the boilerplate of doing so to a minimum.
You may have noticed the lack of fields or properties on our class – by being completely stateless, we allow the backend to manage the creation and ushering of techniques, which we simply respond to on request.
appendBatchPreamble exists to append material-specific UBOs to the batch before draws from culling are appended. We let the material list (i.e. SmartGpuBuffer) handle this itself since it’s a common operation, but we could add whatever other UBOs we wanted.
Both getStride and appendBatchPreamble accept a matCaseBits parameter. This is to enable different GPU material formats depending on the case – e.g. an effect material whose instances have a “variable size” array of texture samplers.
There is game-specific code that provides helper methods to minimize boilerplate and standardize the “attribute interface” across the game’s shaders – this is probably how most games will want to approach things, assuming they have more than one material type. It’s even possible to define multiple “namespaces” within a game this way.
And last but not least, some snippets of the material type’s fragment shader:
#version 150
#include "util/matrix"
#include "gbuffer/write" // declares and writes out attributes
#ifdef MAT_BLOCK_TYPE // do we even have a material block?
#define MAT_TYPE MaterialPbrStruct // use this type
#include "material/pbr" // define our specific material
#include "material/auto" // general material code using the above's #defines
#define MATERIAL 1 // yes we have a material
#endif
#ifdef ALPHA_ATTR
#include "util/screendoor_alpha"
#endif
//...
#ifdef EXTRA_COLOR_SAMPLER
uniform SAMPLER_TYPE EXTRA_COLOR_SAMPLER;
#endif
#ifdef EXTRA_COLOR_ATTR
in vec3 ATTR(ExtraColor);
#endif
//...
void main() {
#ifdef MATERIAL
MAT_TYPE mat = GET_MATERIAL;
#endif
#ifdef GET_ALPHA
float alpha = GET_ALPHA;
#else
float alpha = 1.0;
#endif
#ifdef MATERIAL
alpha *= mat.colorRgba.a;
#endif
// ...you get the idea!
writeFragment( albedoOut, normalOut, extraColorOut, ... );
}About what you’d expect: a lot of #ifdefs and brittle code – but the tradeoff is modularity and overall reduced top-level code, which for something like a PBR material is well worthwhile.
One critical implementation difficulty is the use of #include, which GLSL does not provide. Implementing this with correct reporting of line numbers in error messages is hard enough (see the #line directive), but the real issue is the order of preprocessing: naively substituting each macro before submitting to the GL will result in expansion regardless of surrounding macro logic. This in turn will interfere with pre-parsing due to duplicate variable declarations, or fail to compile due to “once only” #include expansion, and… you get the idea. The only solution is to either implement your own preprocessing on top of the driver’s or be extremely careful about where you use #include… not fun!
Conclusion
That’s it! Thanks for reading, and hopefully this gives someone ideas for how to implement a material system of their own. In terms of my codebase, there’s plenty more to be done on the back-end, and it’s possible these concepts will change over time as I continue working with them. But I’m confident in this as a long-term solution, and have already seen my efforts rewarded with dramatically reduced code complexity, and a “mix-and-match” approach to authoring models with materials.
By the way, if you really liked this article… consider hiring me!
(Shameless plug, I know.)
Future Work
- As discussed earlier, specifying fragment shaders currently involves a lot of
#definessurrounding every possible input attribute and sampler call. It’s pretty tedious to work with, but something like a scripting or node-based language would allow pruning the abstract syntax tree when inputs aren’t provided, rather than using#defines. Another possibility would be to parse GLSL directly and eliminate “unused” input attributes and referencing code. Any one of these solutions would be FAR more legible than the existing one. - This is implied by the above, but a system for artists to author their own “material types” may be essential for any seriously large project. In the current implementation, this may look like a single
MaterialTypeNodeBasedclass that traverses a tree of nodes to generate the output shader, define the instance GPU “struct,” declare auxiliary UBOs, etc., and aMaterialNodeBasedas well. - Currently, batches may be of any type that implements an interface to be “drawn.” This means the process of registering draws to batches is not currently standardized, and batches must be type-cast beforehand. Unifying the type hierarchy in some sense may allow for performance gains, since we can use contiguous memory layouts for all data rather than exposing classes for manipulation. This may come at the sacrifice of generality, however – the real solution may be to unify “instances” of existing batch types instead.